最近闲暇时间想找点事情做,就想要不学习Cuda编程吧,包好玩的。然后,在Google上找Cuda学习资料时发现了很多人都推荐Oakland National Laboratory的视频以及练习。于是,决定在博客上面做个学习笔记,打发下无聊时光,顺便练习下许久未用的英语。
以下是课程链接:
课程内容(Introduction to CUDA C++)
1. 名称定义
在CUDA编程里通常把GPU叫做Device,CPU叫做Host,因此GPU的memory也叫做Device memroy,CPU的memory也叫做Host memory。而Device Code和Host Code分别是运行在GPU以及CPU上的代码。但这并不意味着GPU的代码和CPU的是分离的,他们通常都是在一起运作的。GPU主要表现在强大的计算能力,CPU需要负责例如磁盘IO,用户IO,网络等,但GPU并不负责这些。

2. 三步流程
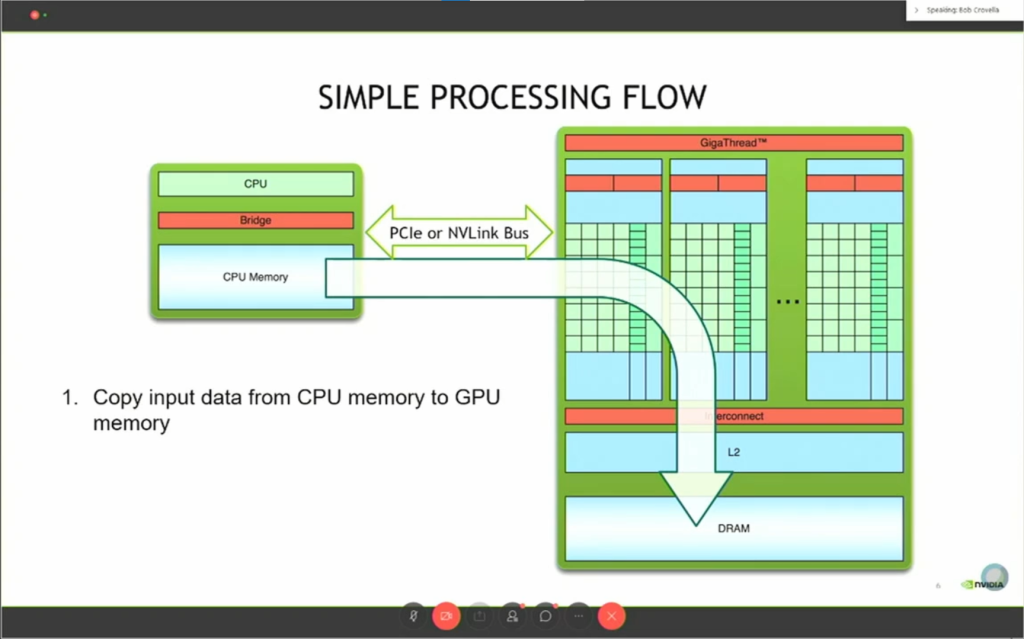
由于CPU和GPU是完全不知道对方在干什么的,我们在CPU代码上定义的数据GPU是不可见的,因此我们需要一些操作去同步两个设备的数据。对此,我们可以用一个简单的三步流程去描述CUDA编程所需要的步骤:
- 将数据从CPU内存复制到GPU内存(图2)
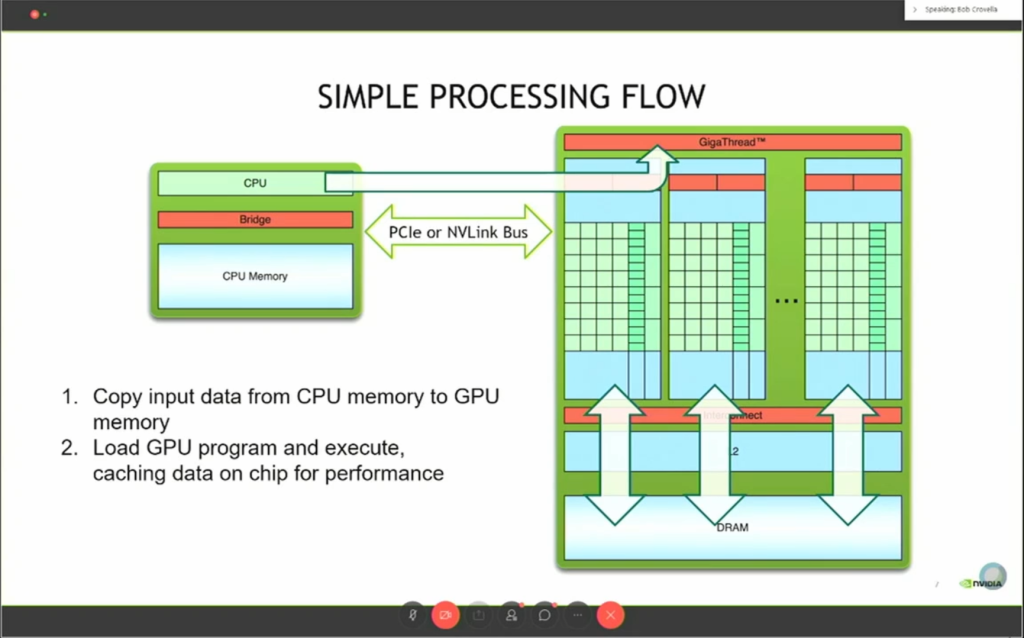
- 加载GPU程序并执行(图3)
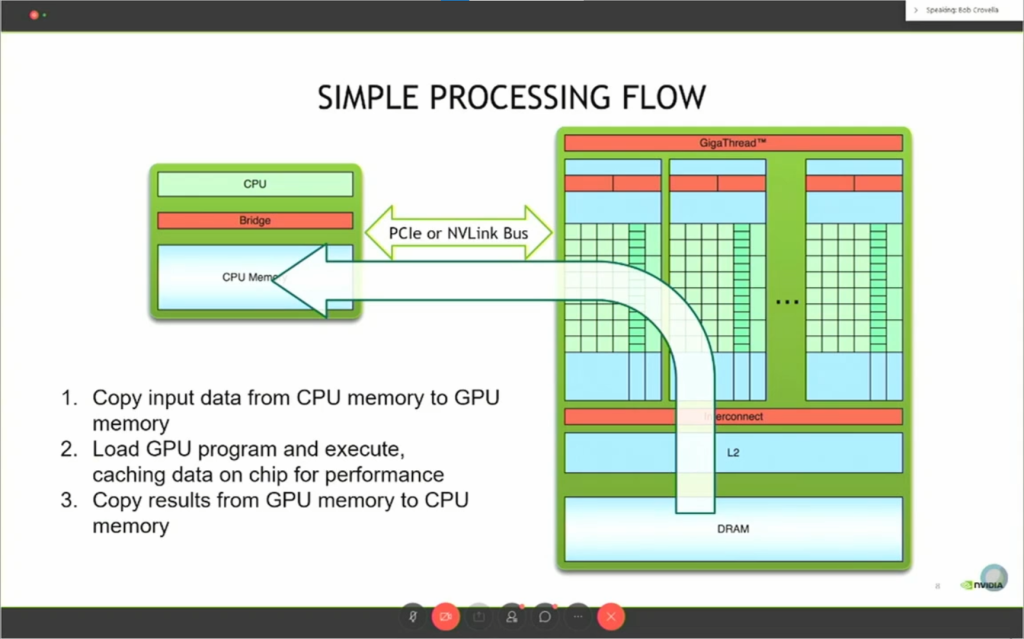
- 将结果从GPU内存复制到CPU内存(图4)
3. 函数定义以及调用
在CUDA编程中通常函数都会带有__global__、__host__或__device__的关键字,并且返回值为void(图5)。通常我们会使用nvcc来编译我们的代码,而nvcc会把源码分成host和device两个部分,分别在英伟达的编译器和c/c++编译器上处理。在调用函数的时候我们需要用到一个CUDA中的语法——“三重尖括号”,也叫做内核启动(kernel launch)(图6),尖括号内的数字代表了启动的核心数以及线程数,代表着我们的程序并行地运行在了多少个核心内。如果我们没有使用这个语法,而是像C/C++一样直接调用函数,那么nvcc就会编译报错。


4. 内建变量(Built-in Variable)
除了__global__,__host__,__device__这几个内建变量,CUDA C++接口还给我们提供了其他的内建变量。在并行计算的时候我们需要知道有多少的线程在工作以及线程的id,这样可以方便我们分配数据以及设计算法。部分解释参考了官方文档。
threadIdx
threadIdx是一个三分量vector,所以threadIdx可以被用作与一维、二维以及三维线程块索引,通过threadIdx我们获取当前线程块内运行的线程id。譬如以下样例,二维矩阵的加法:
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}blockIdx
blockIdx与threadIdx类似也是用来对线程块的索引的,同样的blockIdx也是一个三分量vector,可以表示一到三维的网格(grid)
blockDim
blockDim可以获取线程块的维度,即一个线程块有多少条线程,结合blockIdx,blockDim以及threadIdx,我们可以写一个更加“并行”的矩阵加法:
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}课程练习
Oakland National Laboratory的课程还提供了相应的练习,代码在github上可以找到。我所用的是AMD的显卡,虽然硬件架构不同,但是AMD对自家的异构计算接口(hip)与Nvidia的CUDA库做了大面积的接口映射,所以是需要稍作修改即可在AMD GPU上运行。
hw1 – hello
调用GPU实现打印一个简单的hello world,这个样例可以测试不同大小的block以及thread会对结果有什么影响。
#include <cstdlib>
#include <stdio.h>
#include "hip/hip_runtime.h"
__global__ void hello(){
printf("Hello from block: %u, thread: %u\n", blockIdx.x, threadIdx.x);
}
int main(int argc, char *argv[]){
int griddim = atoi(argv[1]);
int blockdim = atoi(argv[2]);
hello<<<griddim, blockdim>>>();
}使用AMD的hipcc编译程序,并传入不同参数运行:
(base) qibin:~/projects/cuda-training-series/exercises/hw1$ hipcc -o hello hello.cu
(base) qibin:~/projects/cuda-training-series/exercises/hw1$ ./hello 1 1
Hello from block: 0, thread: 0
(base) qibin:~/projects/cuda-training-series/exercises/hw1$ ./hello 2 1
Hello from block: 1, thread: 0
Hello from block: 0, thread: 0
(base) qibin:~/projects/cuda-training-series/exercises/hw1$ ./hello 2 2
Hello from block: 0, thread: 0
Hello from block: 0, thread: 1
Hello from block: 1, thread: 0
Hello from block: 1, thread: 1从结果看传入不同的blockdim*griddim就是总共在GPU上运行的线程数
hw1 – vector_add
使用本章课程讲到的内容实现简单的向量加法。hipMalloc,hipMemcpy相当于C/C++中的Malloc和Memcpy,不同的的是分配内存以及拷贝内存是在GPU上操作的,而hipMemcpyHostToDevice以及hipMemcpyDeviceToHost则是CUDA/hip中的一个枚举类,定义了数据的传输方向,从cpu到gpu或者相反。详情可见官方文档cudaMalloc/cudaMemcpy/cudaMemcpyKind。
以下代码则三步流程中所说的三步处理流程完全相同。橙色高亮代码对应第一步,gpu上分配数据内存并将cpu上的数据复制到gpu上。第二步则是黄色高亮部分,在gpu上进行数据处理。最后蓝色高亮代码为第三步,将数据从gpu挪回cpu。
#include <stdio.h>
#include "hip/hip_runtime.h"
// error checking macro
#define hipCheckErrors(msg) \
do { \
hipError_t __err =hipGetLastError(); \
if (__err !=hipSuccess) { \
fprintf(stderr, "Fatal error: %s (%s at %s:%d)\n", \
msg,hipGetErrorString(__err), \
__FILE__, __LINE__); \
fprintf(stderr, "*** FAILED - ABORTING\n"); \
exit(1); \
} \
} while (0)
const int DSIZE = 4096;
const int block_size = 256; //hip maximum is 1024
// vector add kernel: C = A + B
__global__ void vadd(const float *A, const float *B, float *C, int ds){
int idx = threadIdx.x+blockIdx.x*blockDim.x; // create typical 1D thread index from built-in variables
if (idx < ds)
C[idx] = A[idx] + B[idx]; // do the vector (element) add here
}
int main(){
float *h_A, *h_B, *h_C, *d_A, *d_B, *d_C;
h_A = new float[DSIZE]; // allocate space for vectors in host memory
h_B = new float[DSIZE];
h_C = new float[DSIZE];
for (int i = 0; i < DSIZE; i++){ // initialize vectors in host memory
h_A[i] = rand()/(float)RAND_MAX;
h_B[i] = rand()/(float)RAND_MAX;
h_C[i] = 0;}
hipMalloc(&d_A, DSIZE*sizeof(float)); // allocate device space for vector A
hipMalloc(&d_B, DSIZE*sizeof(float)); // allocate device space for vector B
hipMalloc(&d_C, DSIZE*sizeof(float)); // allocate device space for vector C
hipCheckErrors("cudaMalloc failure"); // error checking
// copy vector A to device:
hipMemcpy(d_A, h_A, DSIZE*sizeof(float), hipMemcpyHostToDevice);
// copy vector B to device:
hipMemcpy(d_B, h_B, DSIZE*sizeof(float), hipMemcpyHostToDevice);
hipCheckErrors("cudaMemcpy H2D failure");
//cuda processing sequence step 1 is complete
vadd<<<(DSIZE+block_size-1)/block_size, block_size>>>(d_A, d_B, d_C, DSIZE);
hipCheckErrors("kernel launch failure");
//cuda processing sequence step 2 is complete
// copy vector C from device to host:
hipMemcpy(h_C, d_C, DSIZE*sizeof(float), hipMemcpyDeviceToHost);
//cuda processing sequence step 3 is complete
hipCheckErrors("kernel execution failure orhipMemcpy H2D failure");
printf("A[0] = %f\n", h_A[0]);
printf("B[0] = %f\n", h_B[0]);
printf("C[0] = %f\n", h_C[0]);
return 0;
}最后结果如下:
(base) qibin:~/projects/cuda-training-series/exercises/hw1$ hipcc -o vector_add vector_add.cu
A[0] = 0.840188
B[0] = 0.394383
C[0] = 1.234571hw1 – matrix_mul
最后这个练习题用一维数组模拟了矩阵乘法,其实核心内容以前面大差不差,但是我认为这个练习给我的收获反而是最深刻的。首先它让我们更加习惯了并行计算的写法,其次则是我一个无意间的改动,让我又收获到了额外的知识。
代码中的核心部分mmul如下:
__global__ void mmul(const float *A, const float *B, float *C, int ds) {
int idx = threadIdx.x+blockDim.x*blockIdx.x; // create thread x index
int idy = threadIdx.y+blockDim.y*blockIdx.y; // create thread y index
if ((idx < ds) && (idy < ds)){
float temp = 0;
for (int i = 0; i < ds; i++)
temp += A[idy*ds+i] * B[i*ds+idx]; // dot product of row and column
C[idy*ds+idx] = temp;
}
}相反的我们如果将黄色高亮部分修改为:
for (int i = 0; i < ds; i++)
temp += A[idx*ds+i] * B[i*ds+idy]; // dot product of row and column
C[idx*ds+idy] = temp;这样类似于将方阵矩阵的行和列调换,但不影响计算结果,但是这两种写法编译后的运行速度却大不相同。从以下结果看,对比于修改前的速度,修改后运行速度足足多了一倍。这个结果让我十分的困惑,因为在我的理解里造成这种现象很有可能是访问非连续内存造成的。但是,从下标计算来看idy*ds+i与idx*ds+i应该都是访问连续的内存空间,而i*ds+idx与i*ds+idy看起来虽然不是访问连续的内存,但是二者的速度应该也是相同的,那究竟是什么因素造成了这一现象?
修改前结果:
(base) qibin:~/projects/cuda-training-series/exercises/hw1$ ./matrix_mul
Init took 0.037945 seconds. Begin compute
Done. Compute took 0.653286 seconds
Success!
修改后结果:
(base) qibin:~/projects/cuda-training-series/exercises/hw1$ ./matrix_mul
Init took 0.040502 seconds. Begin compute
Done. Compute took 1.278184 seconds
Success!通过在Stackoverflow上查找,我找到了一个我认为合理的解释那就是合共访问(coalesced access),以下是原回答的连接:
https://stackoverflow.com/a/5044424
其中一句话:
the correct way to do it is just have consecutive threads access consecutive memory addresses
让连续的线程访问连续的内存地址
以及结合查阅到的关于行优先(row-major order)资料:
https://lumetta.web.engr.illinois.edu/408-S19/slide-copies/ece408-lecture22-S19-ZJUI.pdf
最终我认为合理的解释应该是这样的:
假设blockIdx.x=0, blockIdx.y=0, blockDim=3, gridDim=3,即当前位于block(0, 0),block内有9条线程(3*3),根据row-major order我们可以得到表1。当idx=0,idy=0,那么下标计算等式为idx*ds+i,i*ds+idy,则(0,0), (1,0), (2,0)为相邻线程但存储数据0,3,6并不是连续的,不满足coalesced access;反之如果是idy*ds+i,i*ds+idx,则(0,0), (0,1), (0,2)为相邻线程且存储数据0,1,2是连续的,满足coalesced access。最终会因为coalesced access造成运行速度上的差异。
| 元素idx | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| threadidx(y,x) | (0,0) | (0,1) | (0,2) | (1,0) | (1,1) | (1,2) | (2,0) | (2,1) | (2,2) |
总结
本章节简单地介绍了CUDA中一些简单的概念,如命名,内建变量,同时也简要介绍调用CUDA的流程以及样例。最后课后练习也模拟了矩阵加法、乘法,以及我自己的一点尝试。